%20Redacto%20logo_New.png)
What Is Data Discovery? A Complete Guide to Finding & Mapping Sensitive Data




You cannot protect data you do not know exists. That is the core problem that data discovery solves.
Most organizations store sensitive data across dozens of systems: databases, cloud storage, file servers, SaaS tools, and email archives. Without a systematic process to find it, classify it, and map its movement, compliance becomes guesswork.
What Does Data Discovery Mean?
Data discovery meaning refers to the process of automatically scanning systems and data stores to identify what data exists, where it lives, what type it is, and who has access to it.
The goal is visibility. Before you can comply with GDPR, DPDP, or CCPA, you need to know what personal data you hold, where it is stored, and how it flows through your organization.
Why Data Discovery Matters
Without sensitive data discovery, organizations face several concrete problems:
- They cannot respond accurately to data subject access requests (DSARs)
- They cannot assess the full scope of a data breach
- They cannot enforce data retention and deletion policies
- They cannot prove to regulators that they know what data they hold
- They are likely holding more personal data than they realize
For organizations preparing for India's DPDP Act, completing a data discovery exercise is a practical first step. Knowing what data you hold and where it is located is foundational to building any compliance program.
How the Data Discovery Process Works
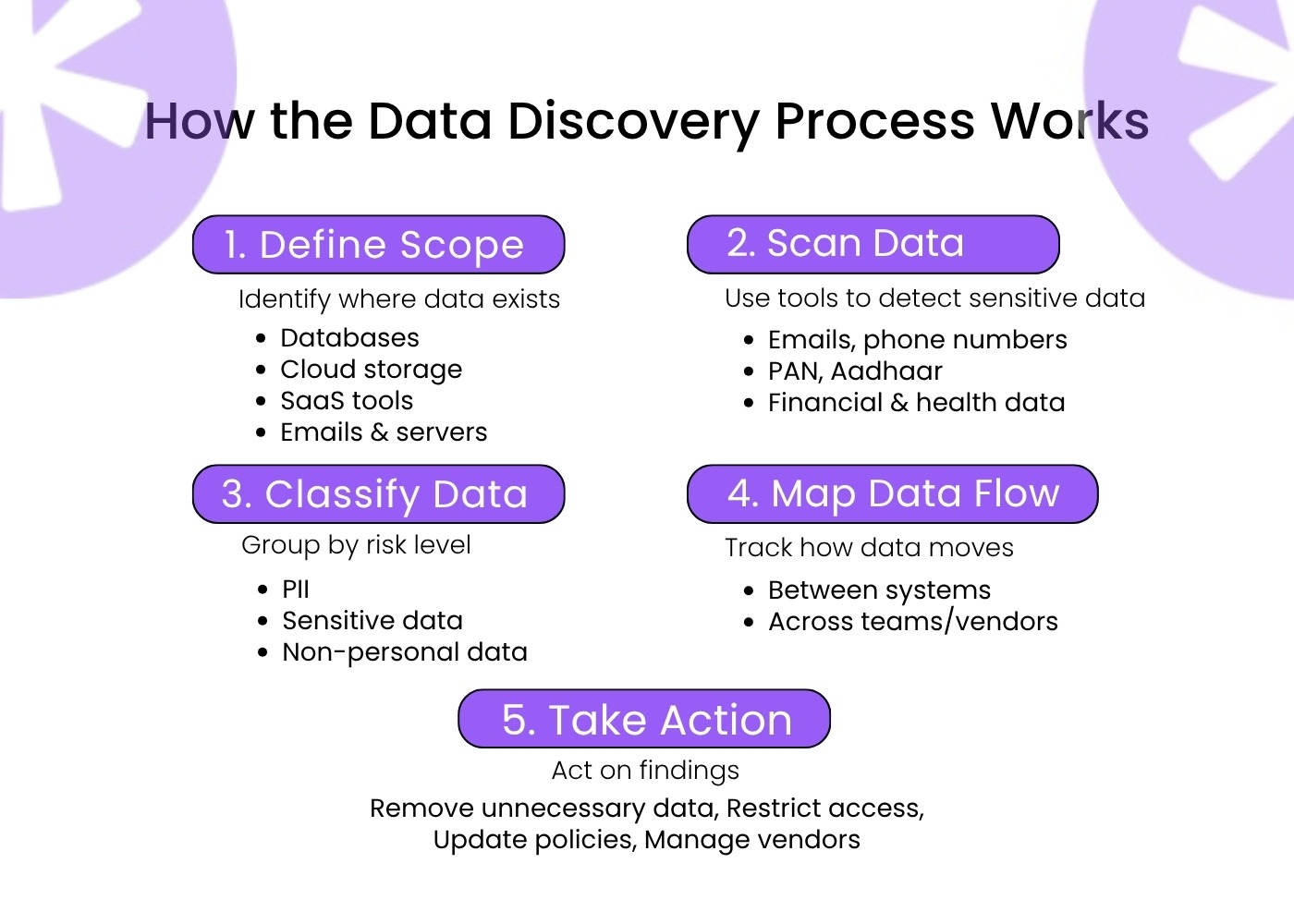
Step 1: Define the Scope
Identify all the systems and data stores that may contain personal or sensitive data. This typically includes:
- Databases (SQL, NoSQL)
- Cloud storage buckets (AWS S3, Azure Blob, Google Cloud)
- SaaS platforms (CRM, HR systems, marketing tools)
- Email and collaboration tools
- On-premise file servers
Step 2: Run Automated Scans
Data discovery tools connect to these systems and scan for data matching predefined patterns. Common examples include names, email addresses, phone numbers, PAN numbers, Aadhaar numbers, credit card numbers, and health records.
Modern tools use machine learning to identify sensitive data, even when it does not match standard patterns, such as personal information embedded in free-text fields.
Step 3: Classify What You Find
Not all data carries the same risk. Classification groups data into categories like:
- Personally Identifiable Information (PII)
- Sensitive Personal Information (financial, health, government ID)
- Non-personal business data
Good data discovery and classification enable you to apply appropriate controls based on risk level.
Step 4: Map Data Flows
Understanding where data goes is as important as knowing where it sits. Data flow mapping traces how personal data moves between systems, who accesses it, and whether it leaves your organization to vendors or third parties.
For GDPR compliance specifically, this mapping forms the basis of your Records of Processing Activities (RoPA). For DPDP compliance, while not explicitly requiring RoPA, detailed processing records are implied through various audit, consent management, and accountability requirements.
Step 5: Act on What You Find
Discovery is only useful if it drives action. Use findings to:
- Remove unnecessary data that should not exist
- Apply access controls to sensitive data stores
- Update your privacy notices to reflect what you actually hold
- Initiate contracts with vendors who handle discovered data
What to Look For in Data Discovery Tools
When evaluating data discovery tools, consider:
- Coverage: Does the tool connect to all your systems, including cloud and SaaS?
- Accuracy: How well does it classify data, especially in unstructured formats?
- Automation: Can it run scans on a schedule and alert on new sensitive data?
- Integration: Does it feed into your broader privacy management workflow?
Conclusion
Data discovery is the starting point for any serious privacy compliance program. Without it, everything else is built on assumptions.
Redacto's AI-driven data discovery module scans, classifies, and maps sensitive data across your organization so your compliance team always knows what they are working with. Contact us to learn more, or chat on WhatsApp for a quick walkthrough.


.png)






